이 강의는 웹크롤링 및 파이썬에 대한 기본 지식이 있어야 원활한 실습이 가능합니다.
중급 강의에서는 기초적인 내용에 대한 설명은 생략하고 작성됩니다.
또한 기초적인 질문에 대해서는 답변을 생략하거나, 링크로 대체함을 알립니다.
이번 강의에서는 커스텀 매매머신의 제작을 위해
젠포트 포트폴리오의 종목을 크롤링 해오는 방법에 대해 설명하겠습니다.

1. 크롤링?
크롤링이란 웹 페이지의 데이터를 가져오는 행위를 이야기합니다.
우리가 젠포트 종목을 다른 목적을 위해 가공할려면
내 포트폴리오에 어떤 종목(데이터)이 있는지 젠포트 홈페이지(웹페이지)에서 가져와야 할 것입니다.
그래서 크롤링을 해 오는 과정이 필요합니다.
2. 어떻게 가져올 것 인가?
우리가 젠포트 홈페이지에서 종목을 어떻게 가져와야 할까요?
포트폴리오에서 어떤 종목이 있는지 확인하는 과정을 생각해 봅시다.
1) 뉴지스탁 홈페이지에 로그인 → 2) 젠포트 홈페이지로 이동 → 3) 내 포트폴리오 리스트 확인
→ 4) 원하는 포트폴리오 클릭 → 5) 매수 대상 종목 확인
의 순서대로 이루어 질 것입니다.
그러면 우리는 이 과정을 파이썬으로 구현하여 표(테이블) 형식으로 가져오면
이것을 기반으로 종목 분석 등을 할 수 있을 것입니다.
3. 구현의 과정
먼저 셀레니움을 사용하기 위해 크롬드라이버를 다운로드합니다.
크롬을 켜서 [설정]탭에 들어간 뒤, [Chrome 정보]에 들어가 크롬 버전을 확인한 뒤,
해당되는 버전의 크롬드라이버를 아래 링크에서 다운로드합니다.

https://chromedriver.chromium.org/downloads
필요한 패키지를 불러오겠습니다.
from selenium import webdriver
from selenium.webdriver.support import expected_conditions as EC
from selenium.webdriver.common.by import By
from selenium.webdriver.support.ui import WebDriverWait
import time
import getpass
import pandas as pdSelenium : 웹페이지에서 젠포트 종목을 크롤링 해 오기위해 사용됩니다.
셀레니움은 웹 앱을 테스트 하기위해 사용되는 패키지로서,
젠포트 홈페이지에서 로그인을 하는 과정이 수반되어야하기 때문에 Beautifulsoap 대신 사용됩니다.
time : 시간 모듈입니다. 로딩을 기다리기 위해 사용됩니다.
getpass : 암호를 보이지 않게 처리해주는 모듈입니다.
키보드입력은 인식하나, 프롬포트상에는 아무것도 입력되지 않는 것 처럼 시현됩니다.
두번째로 로그인 함수를 구현해 보겠습니다.
젠포트 아이디, 비밀번호를 받아서 로그인 한 뒤, 포트번호를 받아서
해당되는 포트에 있는 종목들을 크롤링해올 것이기 때문에,
필요한 정보를 사용자에게 받는 과정이 실시되어야 겠죠?
def get_user_info():
id = input("뉴지스탁 아이디 : ")
pw = getpass.getpass()
port_num = input("매매포트 No. : ")
return [id, pw, port_num]
ID와 포트번호는 암호화 될 필요가 없으므로, 입력을 받아줍니다.
다만 비밀번호는 보이지 않게 처리 할 필요가 있으므로, getpass 모듈을 이용해 암호화 처리를 해줍니다.
그러고 ID, 비밀번호, 포트번호를 묶어서 리스트로 반환시키도록 설계를 해 주었습니다.
세번째로, 홈페이지에 액세스를 해 보겠습니다.
먼저 크롬 드라이버를 연결하여 작성한 코드를 기반으로 원격으로 작동할 수 있게 설정해줍니다.
# 크롬 드라이버 호출
driver = webdriver.Chrome('chromedriver')
driver.implicitly_wait(3)먼저 크롬을 사용할 것이기 때문에 크롬드라이버를 불러옵니다.
* 파일과 같은 위치에 Chromedriver 파일을 받아줍니다.
(2)
그 후 3초간 기다려줍니다.
(이는 브라우저가 실행되었다고 정확히 인식하도록 하기 위함입니다.)
젠포트 홈페이지에서 로그인을 해 보겠습니다.

# 로그인
## 젠포트 홈페이지 접속
driver.get('http://intro.newsystock.com/login/')
## find_element_by_name : html의 이름을 통해 접근
driver.find_element_by_name('ctl00$ContentPlaceHolder1$loginID').send_keys('%s' %id)
driver.find_element_by_name('ctl00$ContentPlaceHolder1$loginPWD').send_keys('%s' %pw)
## find_element_by_xpath : Xpath를 통해 접근, 개발자 도구에서 원하는 곳 선택 후 copy - copy XPath
driver.find_element_by_xpath('//*[@id="ContentPlaceHolder1_btnLogin"]').click()
time.sleep(3)(1)
크롬을 켠 뒤, 로그인 사이트로 접근을 합니다
(2)
이후 ID 칸에 입력받았었던 ID를 입력받은 뒤,
비밀번호 칸에는 입력받은 비밀번호를 입력해줍니다.
(3)
그 후 로그인 버튼을 눌려 로그인을 한 뒤, 3초간 기다려줍니다.
(대기하는 이유는 로딩되는 시간이 있기 때문입니다.)
여기서 구현하는 과정은 빨간색 탭을 누르는 과정입니다.

# 젠포트 포트 관리하기로 접근
## 구현시 주의할 점 : 클릭으로 하지 않고 get로 접근할 경우 로그인 세션이 풀려버린다.
driver.find_element_by_xpath('//*[@id="wrap"]/div[1]/div/div/div/div/div/div[1]/p').click()
driver.find_element_by_xpath('//*[@id="wrap"]/div[1]/div/div/div/div/div/div[2]/ul/li[3]/a').click()
driver.find_element_by_xpath('//*[@id="MasterMainMenu"]/div[3]/p').click()
driver.get('http://genport.newsystock.com/GenPro/PortManage.aspx')
time.sleep(3)(1)
뉴지스탁 메인의 홈페이지의 패밀리사이트 탭을 눌려줍니다.
(제작할때 바로 링크로 들어가니 로그인이 풀리는 경우가 종종 발생하여 이렇게 처리하였습니다.)
(2)
포트 관리하기 페이지로 이동합니다. 그후 3초간 기다려줍니다.
내가 추출할 종목이 있는 포트로 접근해 봅시다.

# 추출할 포트로 접근
driver.find_element_by_xpath('//*[@id="listVT%s"]' %port_num).click()
time.sleep(3)
## 참고링크 : 엘리먼트 클릭이 되지 않을때
## https://wkdtjsgur100.github.io/selenium-does-not-work-to-click/
element = driver.find_element_by_xpath('//*[@id="tabMenu4"]')
driver.execute_script("arguments[0].click();", element)
time.sleep(3)포트번호를 기반으로 가상매매포트에 있는 해당되는 포트의 탭을 클릭합니다.
(2)
매매종목 정보 탭을 클릭합니다.
종목 표를 크롤링해보겠습니다.
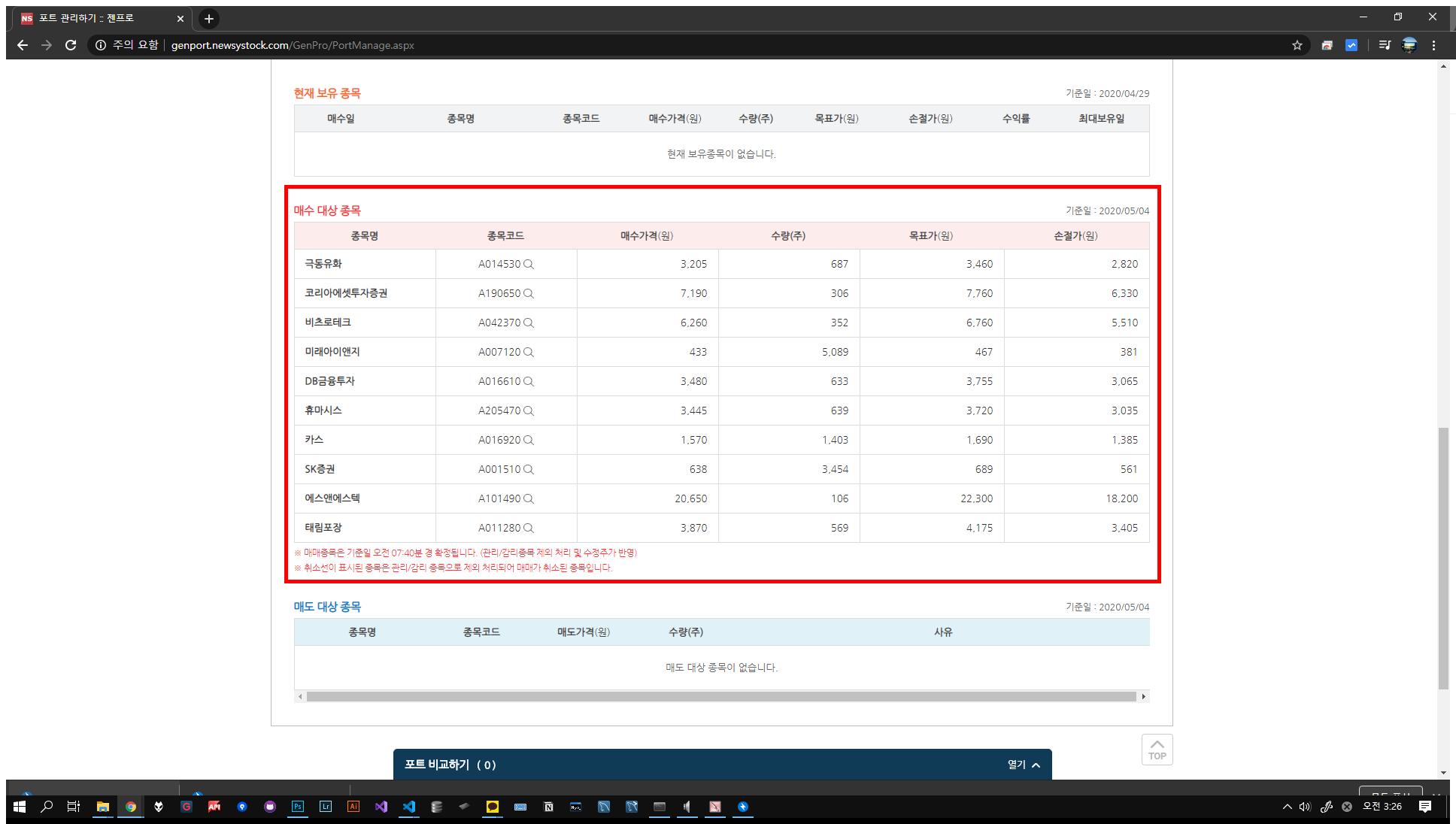
# 종목 표 크롤링
## 참고링크 : https://stackoverflow.com/questions/51273995/selenium-python-dynamic-table (동적 테이블의 크롤링)
## 원리 : 동적 테이블이므로, 테이블 내부 내용이 몽땅 로딩될때까지 대기하였다가 크롤링한다.
elements = WebDriverWait(driver, 10).until(EC.presence_of_all_elements_located(
(By.XPATH, '//*[@id="PortManageSection4"]/div[3]/ul/table')))젠포트를 이용해 보신 분이라면 특정 탭을 눌렸을 때 어느정도 대기를 해야
표 안의 내용이 로딩됨을 알 수 있을 것입니다.
(2)
코드에서도 로딩이 다 되고 종목의 정보를 가져오도록 코드를 작성하겠습니다.
코드에서는 10초내로 XPath 기반으로 종목이 떠있는지 안 떠있는지 체크합니다.
가져온 elements(요소)를 표로 가공하겠습니다.
def divider(l, n):
for i in range(0, len(l), n):
yield(l[i:i+n])(1)
먼저, 리스트를 columns와 value로 나누기 편하게 가공해주는 함수를 만들어줍니다.
## 데이터 전처리
# 데이터프레임으로 추출 (스트링으로 합치고, 스플릿하여 리스트로 바꾼뒤, 데이터프레임으로 바꿈)
temp = str('')
for elements in elements:
temp += elements.text
temp = temp.split()
## print(temp)
trade_list = list(divider(temp, 5))[1:]
column_list = temp[:5]
table = pd.DataFrame(trade_list, columns = column_list) # 데이터프레임은 이놈을 사용하시면 되겠읍니다.
return tabletemp 변수에 elements(포트 종목 데이터)의 텍스트 데이터를 추출하여 저장 합니다.
(2)
split 함수를 이용해 리스트로 가공합니다.
(3)
종목 리스트, 칼럼 리스트로 쪼갠 뒤, 이를 기반으로 데이터프레임으로 가공합니다.

실행하니 종목 형태가 데이터프레임 형태로 출력이 되었습니다.
예제
1) 강의를 바탕으로 코드를 전체를 구현해 봅시다.
2) 포트 정보의 다른 정보를 가져와 봅시다.






